How to Reduce OpenAI API Costs with Semantic Caching có gì mới?
Việc sử dụng API của OpenAI ngày càng phổ biến trong nhiều ứng dụng trí tuệ nhân tạo, tuy nhiên chi phí phát sinh từ việc gọi API có thể là một trở ngại đối với nhiều nhà phát triển và doanh nghiệp. Một giải pháp hiệu quả để giảm thiểu chi phí này là áp dụng kỹ thuật lưu cache ngữ nghĩa (semantic caching), giúp loại bỏ các yêu cầu trùng lặp và giảm lượng token sử dụng. Bài viết từ Medium giới thiệu một cổng kết nối tương thích với OpenAI, cho phép tối ưu hóa quá trình truy vấn API bằng cách lưu trữ và tái sử dụng các kết quả đã có, từ đó tiết kiệm đáng kể chi phí mà vẫn đảm bảo hiệu suất và độ chính xác của hệ thống.
Insight Summary
Tóm tắt nhanh
- Nhiều ứng dụng AI đang tốn tiền vì hỏi đi hỏi lại những câu gần giống nhau.
- Tác giả xây một lớp “ghi nhớ” ở trước API để khỏi gọi lại model cho các câu đã gặp rồi.
- Nếu câu hỏi giống hệt, hệ thống trả luôn đáp án cũ; nếu gần giống, nó tìm theo ý nghĩa rồi mới quyết định.
- Cách này giúp giảm số token dùng, giảm chi phí và đôi khi còn trả lời nhanh hơn.
- Điểm đáng chú ý là ứng dụng gần như không phải sửa nhiều, chỉ đổi sang một địa chỉ API mới.
Bài viết tổng hợp
Khi một ứng dụng dùng AI bắt đầu có người dùng thật, vấn đề thường không nằm ở “AI có thông minh không”, mà là “AI tốn bao nhiêu tiền”. Tác giả bài gốc kể rằng khi làm công cụ dựa trên LLM, anh liên tục thấy người dùng hỏi đi hỏi lại những câu rất giống nhau. LLM là viết tắt của “mô hình ngôn ngữ lớn” — hiểu đơn giản là bộ não AI đứng sau ChatGPT và các hệ thống tương tự. Mỗi lần ứng dụng gửi một câu hỏi lên mô hình, nó phải trả tiền theo lượng chữ đầu vào và đầu ra, thường gọi là token. Token có thể hiểu nôm na là những “mảnh từ” mà AI dùng để đọc và trả lời. Vấn đề là nhiều câu hỏi không hề mới. Có khi người dùng chỉ đổi cách diễn đạt một chút, ví dụ “Làm sao xin quyền truy cập Jira?” và “Tôi không vào được Jira”. Với con người, hai câu này gần như cùng một ý.
Nhưng nếu chỉ nhìn bề mặt chữ, hệ thống thông thường lại coi đó là hai yêu cầu khác nhau và gọi AI thêm một lần nữa. Đây chính là chỗ chi phí âm thầm phình to. Mỗi câu hỏi lặp lại đồng nghĩa với một lần trả tiền mới, dù câu trả lời có thể đã từng được tạo ra trước đó. Nếu lượng truy vấn tăng đều mỗi ngày, khoản chi này có thể lớn hơn nhiều so với dự tính ban đầu. Tác giả đã thử các cách phổ biến trước khi tự xây giải pháp riêng. Redis là một công cụ lưu tạm dữ liệu rất nhanh, nhưng kiểu “cache” truyền thống của nó chỉ hiệu quả khi câu hỏi giống hệt từng ký tự. Nếu người dùng viết khác đi một chút, hệ thống coi như chưa từng thấy. RedisVL là một bước tiến hơn vì có thêm khả năng tìm theo mức độ gần nhau về ý nghĩa. Tuy vậy, để dùng được nó, đội phát triển vẫn phải tự thiết kế luồng lấy “embedding”, đặt cấu trúc dữ liệu, chỉnh ngưỡng giống nhau và tích hợp vào đường đi của request.
Embedding có thể hiểu là cách biến câu chữ thành dạng số để máy tính so sánh mức độ tương đồng về ý nghĩa. Các cơ sở dữ liệu vector như Milvus, Weaviate hay Qdrant cũng làm được chuyện tương tự. Chúng mạnh, nhưng thường phù hợp với bài toán tìm kiếm hoặc phân loại riêng, chứ không phải một lớp đặt thẳng trước API của AI để giảm tiền ngay từ đầu. Nói ngắn gọn, chúng giải quyết được phần “tìm câu gần giống”, nhưng chưa phải một giải pháp “cắm vào là chạy” cho ứng dụng gọi OpenAI.
Từ đó, tác giả chọn cách làm đơn giản hơn
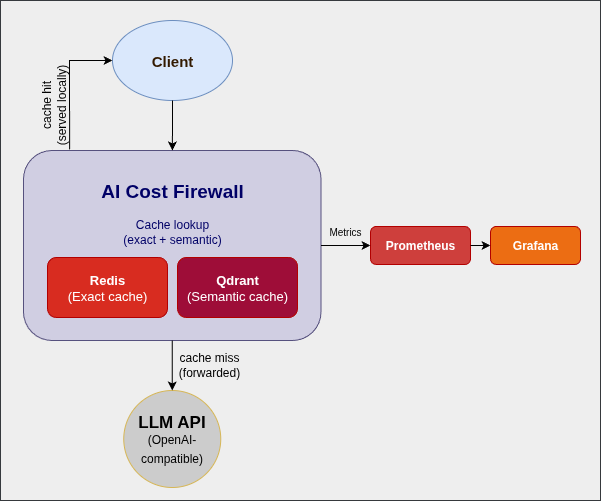
Đặt một lớp trung gian thông minh ở trước mô hình AI. Lớp này được gọi là AI Cost Firewall. Tên nghe có vẻ kỹ thuật, nhưng ý tưởng rất dễ hiểu: nó giống như một “cửa kiểm tra” trước khi yêu cầu đi vào hệ thống AI. Nếu yêu cầu đã từng xuất hiện trước đó, lớp này không gọi AI nữa mà lấy đáp án cũ trả lại. Nếu yêu cầu mới, nó mới chuyển tiếp đến mô hình, nhận kết quả, rồi lưu lại để lần sau dùng tiếp. Mục tiêu là tránh gửi cùng một câu hỏi nhiều lần chỉ để nhận lại cùng một câu trả lời. Điểm hay là ứng dụng phía ngoài gần như không phải thay đổi cách làm việc. Nó vẫn gọi một API trông giống OpenAI như bình thường. Khác biệt nằm ở chỗ đường đi của request đã bị “chặn” qua một lớp tiết kiệm chi phí ở giữa. Tác giả giữ kiến trúc ở mức tối giản để tránh biến giải pháp tiết kiệm thành một dự án cồng kềnh.
Bên trong hệ thống có một API gateway viết bằng Rust, Redis để lưu trùng khớp chính xác, Qdrant để tìm theo mức độ giống về ý nghĩa, còn Prometheus và Grafana dùng để theo dõi số liệu. API gateway có thể hiểu là “cửa nhận và chuyển tiếp yêu cầu”. Nó đứng ở giữa ứng dụng của bạn và dịch vụ AI. Redis là nơi tra cứu cực nhanh các câu đã gặp y hệt nhau. Qdrant là phần giúp nhận ra những câu không giống từng chữ nhưng gần giống về nội dung. Prometheus và Grafana là bộ công cụ quan sát hệ thống. Chúng cho biết có bao nhiêu yêu cầu được trả từ cache, bao nhiêu yêu cầu phải gửi thật lên AI, và ước tính đã tiết kiệm được bao nhiêu tiền. Với người vận hành sản phẩm, các con số này rất quan trọng vì chúng biến “có vẻ tiết kiệm” thành “tiết kiệm được bao nhiêu”. Tác giả chọn Rust cho phần gateway vì đây là lớp nằm ngay trên đường đi của request.
Rust nổi tiếng vì chạy nhanh, ít tốn tài nguyên và ít rủi ro lỗi bộ nhớ so với một số ngôn ngữ khác. Nói đơn giản, khi hệ thống cần trả lời nhanh và ổn định, Rust là lựa chọn hợp lý để không trở thành nút thắt cổ chai. Anh cũng quyết định mở mã nguồn của công cụ này. Lý do không phải để “làm màu công nghệ”, mà vì lớp nằm giữa ứng dụng và nhà cung cấp AI là vị trí rất nhạy cảm. Mở mã nguồn giúp người dùng dễ kiểm tra, dễ tin hơn và dễ chỉnh sửa theo nhu cầu của mình. Việc cài đặt cũng được làm khá ngắn gọn. Theo bài viết, chỉ cần tải mã nguồn, chạy Docker, cấu hình vài thông tin cần thiết rồi đổi địa chỉ API của ứng dụng sang endpoint mới. Endpoint là địa chỉ mà ứng dụng gửi yêu cầu tới; ở đây chỉ là chuyển từ địa chỉ cũ sang địa chỉ của lớp trung gian. Một ví dụ trong bài cho thấy cách tiếp cận này hiệu quả khá nhanh.
Sau khi áp dụng, tác giả thấy một phần đáng kể request được trả từ cache thay vì gọi AI lại. Điều đó giúp giảm token tiêu thụ và cải thiện tốc độ phản hồi ở các lượt có thể dùng lại dữ liệu. Điều đáng chú ý là tác giả không cần tối ưu prompt hay đổi sang model khác mới thấy khác biệt. Chỉ riêng việc ngăn các yêu cầu lặp lại đã tạo ra thay đổi rõ rệt. Với nhiều đội sản phẩm, đây là điểm rất thực tế: không phải lúc nào cũng cần giải pháp phức tạp, đôi khi chỉ cần đừng làm lại cùng một việc. Tác giả cũng dùng dashboard để nhìn trực tiếp hiệu quả của hệ thống. Bảng này hiển thị tỷ lệ cache hit — tức là bao nhiêu yêu cầu được trả lời từ bộ nhớ tạm thay vì gọi AI. Ngoài ra còn có số token tiết kiệm và chi phí ước tính theo thời gian thực.
Điều này dẫn đến vài ý rất dễ áp dụng
- Nếu ứng dụng của bạn có nhiều câu hỏi hỗ trợ khách hàng, khả năng cao có rất nhiều câu trùng ý.
- Nếu mỗi lần nhúng AI vào luồng xử lý đều tốn tiền, việc chặn các câu lặp sẽ tạo khác biệt rõ.
- Nếu bạn không muốn sửa quá nhiều code, một lớp trung gian phía trước API thường dễ triển khai hơn thay vì thay toàn bộ ứng dụng.
- Nếu hệ thống cần phản hồi nhanh, trả lời từ cache luôn nhanh hơn gọi AI thật.
- Nếu bạn cần theo dõi chi phí, hãy đo số request được tái sử dụng thay vì chỉ nhìn tổng tiền cuối tháng.
Bài viết cũng cho thấy một ranh giới quan trọng giữa “tìm kiếm theo ý nghĩa” và “cache thông minh”. Tìm kiếm theo ý nghĩa nghĩa là tìm các câu gần giống về nội dung. Cache thông minh nghĩa là khi đã nhận ra câu hỏi đủ giống, hệ thống không cần suy nghĩ lại từ đầu mà dùng lại câu trả lời cũ. Nói cách khác, mục tiêu không phải thay AI bằng một hệ thống khác thông minh hơn. Mục tiêu là để AI chỉ làm việc khi thật sự cần. Với những bài toán hỗ trợ nội bộ, hỏi đáp thường gặp, trợ lý công ty hay bot chăm sóc khách hàng, phần lớn chi phí có thể đến từ những câu đã biết trước. Một điểm thực tế khác là giải pháp này không giải quyết mọi trường hợp. Nếu câu hỏi cũ nhưng bối cảnh đã đổi, trả lại câu trả lời cũ có thể không phù hợp. Vì vậy, lớp cache kiểu này cần được thiết kế cẩn thận, chọn đúng loại câu hỏi và ngưỡng giống nhau phù hợp.
Tuy vậy, thông điệp lớn của bài viết khá rõ
Chi phí AI không nhất thiết phải giảm bằng việc đổi sang model rẻ hơn hoặc viết prompt hay hơn. Đôi khi, cách tiết kiệm nhất là không gọi model thêm lần nữa nếu câu trả lời đó đã tồn tại rồi.
Vì sao nên đọc các bài tóm tắt trên Insight
Đọc nguyên một bài kỹ thuật thường mất nhiều thời gian, nhất là khi bài có nhiều thuật ngữ, công cụ và ví dụ triển khai. Insight giúp bạn đi thẳng vào điều quan trọng nhất: vấn đề là gì, giải pháp ra sao, và nó có ý nghĩa thực tế thế nào với người dùng hoặc doanh nghiệp. Với các chủ đề như AI, startup hay phần mềm, bài gốc thường dành cho người đã quen công nghệ. Bản tóm tắt của Insight chuyển những khái niệm như token, cache, vector search hay API gateway sang ngôn ngữ dễ hiểu hơn, để bạn nắm ý nhanh mà không cần đọc hết phần kỹ thuật. Điều này đặc biệt hữu ích nếu bạn là người làm sản phẩm, kinh doanh, vận hành, nội dung hoặc quản lý. Bạn vẫn hiểu được xu hướng, cách các nhóm kỹ thuật đang giải quyết vấn đề, và điểm nào có thể áp dụng vào công việc của mình mà không bị ngợp trong chi tiết. Quan trọng hơn, Insight giúp lọc nhiễu.
Bạn không cần mất công phân biệt đâu là phần quảng bá, đâu là phần thật sự có giá trị, đâu là chi tiết triển khai chỉ dành cho kỹ sư. Chúng tôi cô đọng lại ý chính, giữ đúng tinh thần bài gốc, và trình bày ngắn gọn để bạn có thể đọc trên điện thoại trong vài phút. Nếu bạn muốn theo dõi nhanh những thay đổi đáng chú ý trong AI và công nghệ, đây là cách tiết kiệm thời gian mà vẫn không bỏ lỡ điều cốt lõi.
Nguồn bài viết
Insight Graph
Khám phá hệ sinh thái 1997 Studio
Nếu bạn đang xây sản phẩm hoặc tăng trưởng, có thể tham khảo thêm các công cụ trong hệ sinh thái để áp dụng nhanh những insight này.
Bài liên quan