O iFood tem 10 trilhões de tokens. Eu tinha uma ideia de fim de semana. có gì mới?
Vào một buổi tối thứ sáu, khi đang nghe một podcast, tôi chợt nhận ra điều gì đó quan trọng liên quan đến iFood và số lượng token khổng lồ mà họ sở hữu, lên đến 10 nghìn tỷ. Ý tưởng này đã khơi dậy trong tôi một suy nghĩ về tiềm năng và cách thức ứng dụng các token trong hệ sinh thái sản phẩm. Bài viết sẽ cùng khám phá những khía cạnh liên quan đến việc sử dụng token trong lĩnh vực thiết kế sản phẩm, cũng như những cơ hội và thách thức mà nó mang lại trong tương lai.
Insight Summary
Tóm tắt nhanh
- Tác giả nảy ra ý tưởng cải thiện catalog sản phẩm sau khi nghe về cách iFood dùng dữ liệu để cá nhân hóa trải nghiệm.
- Thay vì làm hệ thống phức tạp, cô chọn giải pháp đơn giản chạy ngay trên trình duyệt.
- Catalog mới nhớ những gì người dùng đã xem, đã tìm và hay bấm vào để gợi ý phù hợp hơn.
- Tất cả dữ liệu được lưu trong máy người dùng, không gửi lên máy chủ.
- Bài học chính: không phải lúc nào cũng cần giải pháp “khủng”, đôi khi một bản làm đúng vấn đề đã đủ tốt.
Bài viết tổng hợp
Một buổi tối cuối tuần, tác giả nghe podcast và biết về hệ thống cá nhân hóa của iFood. Điều khiến cô chú ý không chỉ là con số dữ liệu rất lớn, mà là kết quả: người dùng được gợi ý đúng hơn, mua hàng nhiều hơn. Cảm hứng đó khiến cô nhìn lại sản phẩm catalog mà mình đang làm. Catalog này có giao diện gọn, tìm kiếm chạy được, sản phẩm được sắp xếp ổn. Nhưng nó đối xử gần như giống nhau với mọi người, dù mỗi người vào trang với nhu cầu rất khác. Với người không chuyên công nghệ, “cá nhân hóa” có thể hiểu đơn giản là: hệ thống biết bạn đã xem gì, thích gì, hay tìm gì, rồi tự điều chỉnh nội dung cho hợp hơn. Không phải để theo dõi người dùng một cách phức tạp, mà để bớt bắt họ làm lại những việc đã làm rồi. Vấn đề của catalog cũ là khá quen thuộc. Người dùng vào xem vài món, rồi quên mất món nào đã mở.
Họ phải tìm lại, đổi từ khóa, mở đi mở lại nhiều lần, và cuối cùng có thể rời trang mà chưa mua gì. Tác giả nhận ra điều lớn nhất không nằm ở công nghệ cao siêu, mà ở cách đặt câu hỏi đúng. Thay vì nghĩ ngay đến máy chủ, trí tuệ nhân tạo hay hệ thống phân tích dữ liệu lớn, cô tự hỏi: mình thực sự cần biết gì về người dùng để giúp họ nhanh hơn?
Câu trả lời khá đơn giản
- Họ đã xem sản phẩm nào.
- Họ hay tìm từ khóa nào.
- Họ thường bấm vào danh mục nào.
- Họ đang ở bước nào trong hành trình mua hàng.
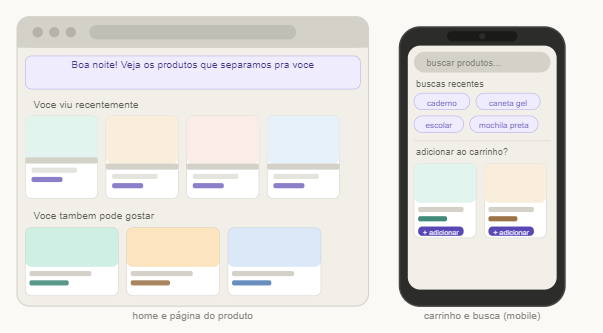
Từ đó, cô xây dựng một bản thử nghiệm nhỏ gọi là Smart Catalog Agent. Đây là phiên bản đầu tiên của một catalog “biết học” từ hành vi người dùng, nhưng làm theo cách rất nhẹ và dễ triển khai. Điểm hay của ý tưởng này là nó không cần hệ thống dữ liệu lớn hay mô hình học máy phức tạp. Tất cả có thể chạy ngay trên frontend, tức là phần giao diện và logic nằm ở trình duyệt của người dùng. Nói dễ hiểu hơn, thay vì gửi dữ liệu của người dùng lên máy chủ để tính toán, ứng dụng tự ghi nhớ những gì cần thiết ngay trong trình duyệt. Công cụ dùng để lưu tạm thông tin này là localStorage, một vùng nhớ nhỏ trong trình duyệt web. localStorage có thể hiểu như một cuốn sổ tay rất đơn giản mà trang web để lại trên máy người dùng. Nó chỉ giữ lại vài thông tin cơ bản, đủ để lần sau mở lại thì trang “nhớ” được phần nào hành vi trước đó. Từ nền tảng đó, tác giả làm ra một số tính năng thực tế.
Không phức tạp, nhưng hữu ích.
- Hiển thị những sản phẩm người dùng đã xem gần đây ngay ở trang chủ hoặc trang sản phẩm.
- Gợi ý sản phẩm dựa trên nhóm danh mục mà người dùng thường truy cập.
- Đề xuất thêm món liên quan trong giỏ hàng để tăng cơ hội mua kèm.
- Lưu lịch sử tìm kiếm dưới dạng nút bấm nhanh để người dùng không phải gõ lại.
- Chào người dùng theo thời điểm trong ngày để trải nghiệm tự nhiên hơn.
Mục tiêu của các tính năng này không phải làm “thông minh” theo kiểu phô trương. Mục tiêu là giảm ma sát, tức là giảm những bước thừa khiến người dùng mất công, mất thời gian hoặc mất hứng mua hàng. Điều quan trọng là toàn bộ cách làm này không cần hạ tầng bổ sung. Nghĩa là không phải đầu tư thêm máy chủ, không phải xây pipeline dữ liệu, cũng không phải tốn chi phí vận hành lớn cho giai đoạn đầu.
Có thể tóm gọn cách hoạt động của bản thử nghiệm này như sau
- Trình duyệt lưu lại một số hành vi cơ bản.
- Hệ thống đếm tần suất xem, tìm, bấm vào danh mục.
- Những mục xuất hiện nhiều hơn sẽ được ưu tiên hiển thị.
- Dữ liệu được cập nhật dần, không phải tính lại toàn bộ mỗi lần người dùng bấm.
- Người dùng có thể xóa lịch sử bất kỳ lúc nào.
Cách làm này gắn với một nguyên tắc rất quan trọng
Bảo vệ quyền riêng tư ngay từ thiết kế. “Privacy by Design” nghe có vẻ chuyên môn, nhưng ý nghĩa khá đơn giản: thay vì thu thật nhiều dữ liệu rồi mới tìm cách bảo vệ sau, ta thiết kế hệ thống sao cho ngay từ đầu đã chỉ dùng đúng phần dữ liệu cần thiết. Ở đây, tác giả không thu dữ liệu nhạy cảm vì thật ra không cần. Nếu mục tiêu chỉ là gợi ý tốt hơn trong catalog, thì lịch sử xem, tìm kiếm và danh mục đã đủ để tạo ra trải nghiệm hữu ích. Một điểm đáng chú ý khác là cô không cố làm bản hoàn hảo ngay từ đầu. Cô chấp nhận đây mới chỉ là MVP, tức là phiên bản thử nghiệm tối thiểu để kiểm tra ý tưởng có thật sự hữu ích hay không.
MVP là cách làm sản phẩm rất phổ biến
Thay vì chờ đủ mọi thứ rồi mới ra mắt, hãy làm phiên bản nhỏ nhất nhưng dùng được. Sau đó mới quan sát phản hồi thật, rồi mới quyết định có nên mở rộng hay không. Ý tưởng này cho thấy một cách suy nghĩ khá thực tế trong làm sản phẩm: đừng bắt đầu từ câu hỏi “mình có thể xây hệ thống lớn đến đâu”, mà hãy bắt đầu từ câu hỏi “người dùng đang gặp khó gì”.
Từ câu chuyện của tác giả, có thể rút ra vài điểm chính
- Hệ thống lớn không phải lúc nào cũng cần thiết cho bước đầu.
- Giải pháp đơn giản đôi khi lại giúp người dùng rõ nhất.
- Cần ưu tiên trải nghiệm thực tế hơn là ấn tượng kỹ thuật.
- Quyền riêng tư nên được tính ngay từ lúc thiết kế.
- Làm được bản chạy ổn hôm nay thường giá trị hơn ý tưởng lớn chưa ra khỏi bản nháp.
Cũng cần nói rõ rằng bản này có giới hạn. Nó chưa có các tính năng nâng cao như so sánh sở thích giữa nhiều người dùng, chưa có thử nghiệm A/B để đo hiệu quả thật, và cũng chưa có hệ thống phân tích tập trung. A/B test là cách thử hai phiên bản khác nhau của cùng một tính năng để xem bản nào hiệu quả hơn. Ví dụ, một nhóm người dùng thấy gợi ý cũ, nhóm khác thấy gợi ý mới, rồi đội sản phẩm so kết quả. Collaborative filtering là kiểu gợi ý dựa trên hành vi của nhiều người giống nhau. Nói ngắn gọn, nếu nhiều người có thói quen tương tự bạn thích một món nào đó, hệ thống có thể gợi ý món ấy cho bạn. Search semantical, hay tìm kiếm ngữ nghĩa, là kiểu tìm không chỉ dựa trên từ khóa giống y chang, mà còn hiểu ý gần đúng của người dùng. Đây là bước nâng cao hơn, nên tác giả để dành cho sau.
Dù vậy, bài viết vẫn cho thấy một tư duy rất đáng giá
Đừng để ngưỡng “phải thật lớn” làm mình tê liệt. Một giải pháp nhỏ, sống được, dùng được, học được từ người dùng thật thường là khởi đầu tốt nhất. Có thể hiểu toàn bộ câu chuyện như một bài học về sản phẩm số:
- Người dùng không cần biết hệ thống phía sau to hay nhỏ.
- Họ chỉ cần bớt phải tìm lại, bớt phải nhập lại, bớt phải đoán mò.
- Nếu hệ thống hiểu được thói quen cơ bản của họ, trải nghiệm sẽ mượt hơn rõ rệt.
- Nếu làm điều đó mà không xâm phạm quyền riêng tư, sản phẩm càng đáng tin.
- Và nếu có thể làm ngay trên trình duyệt, càng dễ thử nghiệm nhanh.
Điều tác giả học được từ iFood không phải là công thức sao chép. Đó là cách nhìn vấn đề: lấy việc hiểu người dùng làm trung tâm, rồi chọn công nghệ vừa đủ để giải quyết nó. Đây cũng là điều nhiều nhóm sản phẩm hay bỏ qua. Họ dễ bị cuốn vào câu hỏi “dùng công nghệ gì”, trong khi câu hỏi đúng nên là “người dùng đang vướng ở đâu”. Nếu câu hỏi đúng, giải pháp thường sẽ gọn hơn nhiều. Khi đó, localStorage, một vài phép đếm, một vài quy tắc đơn giản có thể đủ để tạo ra trải nghiệm tốt hơn hẳn so với một hệ thống phức tạp nhưng chưa chắc dùng được ngay.
Vì sao nên đọc các bài tóm tắt trên Insight
Insight giúp bạn nắm ý chính của một bài dài mà không phải đọc hết từng chi tiết kỹ thuật hay những đoạn lan man dễ làm mất tập trung. Với người bận rộn, đây là cách tiết kiệm thời gian rất rõ ràng: chỉ cần vài phút là biết tác giả đang nói gì, làm gì, và vì sao điều đó quan trọng. Ngoài ra, Insight còn giúp lọc nhiễu. Nhiều bài gốc có thể chứa thuật ngữ, ví dụ kỹ thuật, hoặc cách diễn đạt mang tính cá nhân rất mạnh. Bản tóm tắt sẽ chắt lại phần cốt lõi, giải thích bằng ngôn ngữ dễ hiểu, để người không chuyên vẫn theo được mạch ý. Lợi ích lớn nhất là bạn vẫn nắm được bài học thực tế mà không bị ngợp bởi chi tiết. Khi cần, bạn có thể quyết định đọc tiếp bài gốc hoặc bỏ qua mà không thấy “thiếu thông tin”. Đây là cách đọc phù hợp hơn với nhịp làm việc nhanh, đặc biệt với nội dung về sản phẩm, thiết kế và công nghệ.
Nguồn bài viết
Insight Graph
Khám phá hệ sinh thái 1997 Studio
Nếu bạn đang xây sản phẩm hoặc tăng trưởng, có thể tham khảo thêm các công cụ trong hệ sinh thái để áp dụng nhanh những insight này.
Bài liên quan